Hướng dẫn Zip Multiple Files để Download from AWS S3
5th Oct 2022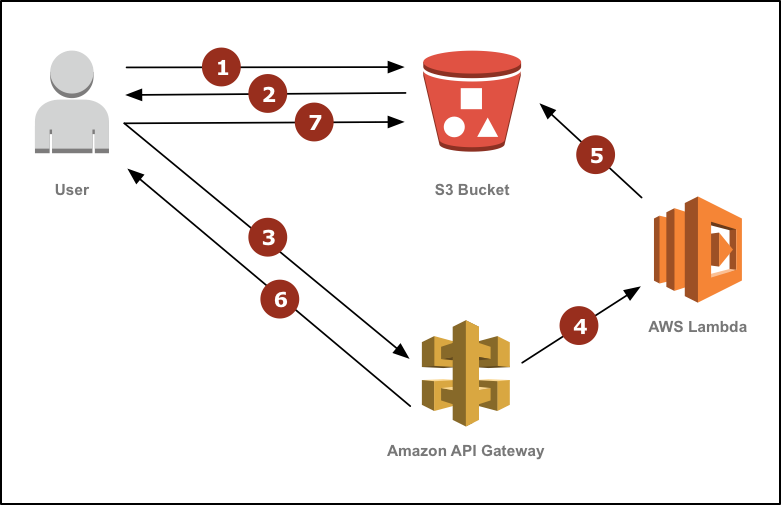







Gần đây, chúng tôi đã quyết định tại Lingo rằng chúng tôi muốn cho phép khách hàng của mình tải xuống nhiều tệp nội dung cùng một lúc. Chúng tôi lưu trữ tất cả nội dung trong AWS S3, AWS S3 không cung cấp phương pháp truy xuất nhiều tệp cùng lúc trong một tệp zip. (Tại sao không!?)
Tôi đã thực hiện một số tìm kiếm trên Google và tìm thấy một giải pháp Python có mục đích hoạt động theo cách lý tưởng nhất: không sử dụng bộ nhớ và không sử dụng đĩa. Làm sao có thể? Nó giống như ma thuật. Về cơ bản, ý tưởng là bạn phát trực tiếp các tệp từ S3, trực tiếp vào một tệp zip đang truyền trực tuyến tới S3 khi bạn thêm tệp vào đó. (Nghe vẫn giống như ma thuật đen.)
Câu chuyện ngắn, điều này không hoạt động trong Python. Tôi không biết tại sao, khi tôi theo dõi một vài ví dụ từ internet. Bất cứ ai cho rằng nó hoạt động hẳn đã không kiểm tra nó kỹ lưỡng, hoặc đang bị ảo tưởng, bởi vì nó chắc chắn đã sử dụng bộ nhớ khi nó đang xây dựng tệp zip. Với các tệp đủ lớn hoặc một số lượng lớn các tệp nhỏ, toàn bộ sự cố.
Lo lắng vì Python quý giá của tôi đã không làm tôi thất vọng, tôi đã tìm thấy một số nguồn trên internet cho rằng ý tưởng này đã hoạt động khi sử dụng Node và hoạt động đặc biệt tốt như một hàm AWS Lambda. Điều này nghe có vẻ là một ý kiến hay đối với tôi, bởi vì một hàm Lambda chắc chắn sẽ không cho phép bạn sử dụng quá nhiều bộ nhớ, không gian đĩa hoặc thời gian. Chỉ có một vấn đề là tôi không biết chút gì về phát triển Node / JavaScript. Tôi đoán đã đến lúc phải học!
Vì vậy, ... tôi đã học được. Một câu chuyện ngắn (một lần nữa), cần một chút nghiên cứu, nhưng tôi đã nghĩ ra hàm Lambda này, nó nén thành công hàng trăm tệp trực tiếp vào một tệp zip trên S3, mà không cần sử dụng bộ nhớ thực và chắc chắn không sử dụng đĩa. Phải mất một số nghiên cứu, bởi vì không có ví dụ nào mà mọi người đã đăng trực tuyến thực sự hoạt động hoàn hảo từ đầu đến cuối. Đối với tất cả những gì tôi biết, tập lệnh này có một số vấn đề, nhưng tôi chưa gặp phải chúng và khi tôi gặp phải, tôi sẽ cập nhật nó để tránh chúng.
// Lambda S3 Zipper
// http://amiantos.net/zip-multiple-files-on-aws-s3/
//
// Accepts a bundle of data in the format...
// {
// "bucket": "your-bucket",
// "destination_key": "zips/test.zip",
// "files": [
// {
// "uri": "...", (options: S3 file key or URL)
// "filename": "...", (filename of file inside zip)
// "type": "..." (options: [file, url])
// }
// ]
// }
// Saves zip file at "destination_key" location
"use strict";
const AWS = require("aws-sdk");
const awsOptions = {
region: "us-east-1",
httpOptions: {
timeout: 300000 // Matching Lambda function timeout
}
};
const s3 = new AWS.S3(awsOptions);
const archiver = require("archiver");
const stream = require("stream");
const request = require("request");
const streamTo = (bucket, key) => {
var passthrough = new stream.PassThrough();
s3.upload(
{
Bucket: bucket,
Key: key,
Body: passthrough,
ContentType: "application/zip",
ServerSideEncryption: "AES256"
},
(err, data) => {
if (err) throw err;
}
);
return passthrough;
};
// Kudos to this person on GitHub for this getStream solution
// https://github.com/aws/aws-sdk-js/issues/2087#issuecomment-474722151
const getStream = (bucket, key) => {
let streamCreated = false;
const passThroughStream = new stream.PassThrough();
passThroughStream.on("newListener", event => {
if (!streamCreated && event == "data") {
const s3Stream = s3
.getObject({ Bucket: bucket, Key: key })
.createReadStream();
s3Stream
.on("error", err => passThroughStream.emit("error", err))
.pipe(passThroughStream);
streamCreated = true;
}
});
return passThroughStream;
};
exports.handler = async (event, context, callback) => {
var bucket = event["bucket"];
var destinationKey = event["destination_key"];
var files = event["files"];
await new Promise(async (resolve, reject) => {
var zipStream = streamTo(bucket, destinationKey);
zipStream.on("close", resolve);
zipStream.on("end", resolve);
zipStream.on("error", reject);
var archive = archiver("zip");
archive.on("error", err => {
throw new Error(err);
});
archive.pipe(zipStream);
for (const file of files) {
if (file["type"] == "file") {
archive.append(getStream(bucket, file["uri"]), {
name: file["filename"]
});
} else if (file["type"] == "url") {
archive.append(request(file["uri"]), { name: file["filename"] });
}
}
archive.finalize();
}).catch(err => {
throw new Error(err);
});
callback(null, {
statusCode: 200,
body: { final_destination: destinationKey }
});
};
So với Python, cú pháp Javascript là một mớ hỗn độn kinh khủng khiến tôi chảy máu mắt. Nhưng tôi không thể tranh luận với kết quả, điều này đã thành công trong khi giải pháp Python thì không.
Nếu bạn cần giải thích về những gì mã này làm được, chỉ cần dành cho mình một hoặc hai năm với tư cách là một nhà phát triển chuyên nghiệp và bạn sẽ hiểu những gì nó không đặc biệt quan trọng, nhưng đến lúc đó bạn sẽ có thể tìm ra .

Add new comment